Averages deceive: birth control is better than the NYT credits ★
Update (2020): This is still a valuable piece of analysis that is basically correct, so I’m leaving it up. But I want to add two notes.
-
To correct a false inference that I make in the introduction: that because you hear of few unplanned pregnancies, they are rare. That’s wrong for two reasons: first, parents often won’t admit that a pregnancy is unplanned; second, terminations are pretty common and nearly always kept private. So you can’t infer much about unplanned pregnancies from everyday experience.
-
To amend my tone: I’m too flippant about which people experience contraceptive failure. That probably has a lot to do with lack of education, poverty, and disempowerment of women. “Foolishness” is a bad way to describe these factors. I would write this differently today.
Update (16 Sep): This piece has become unexpectedly popular, which is a great but in retrospect I should have been more careful in my explanation. The point, and my numerical reasoning, stand, but to be clear: the problem is aggregation—the NYT’s implicit assumption of 100 couples each of which faces the group-average single-year effectiveness—and not dependence. Given 100 identical couples like that, their analysis is fine. The problem is that, in reality, a draw of 100 random couples (or indeed the entire population) will not be like that: some will be careful and some will be careless, and now you can’t just take a ‘representative couple’ and multiply by 100. It’s effectively an instance of the ecological fallacy, though I don’t know if it has a particular name. In bringing dependence and independence into it below, I’m confusing things unnecessarily.
I’ve written a very short mathematical note for those who prefer precision.
A piece in the NYT, by Gregor Aisch and Bill Marsh, purports to show the rate of unplanned pregnancy for different contraceptive methods, over a ten-year timespan. For example, for male condoms, they calculate that “For every 100 women, the number who will have an unplanned pregnancy over ten years is 86.” Even for the pill, which is considered extremely reliable, they claim 61% of couples will conceive in ten years.
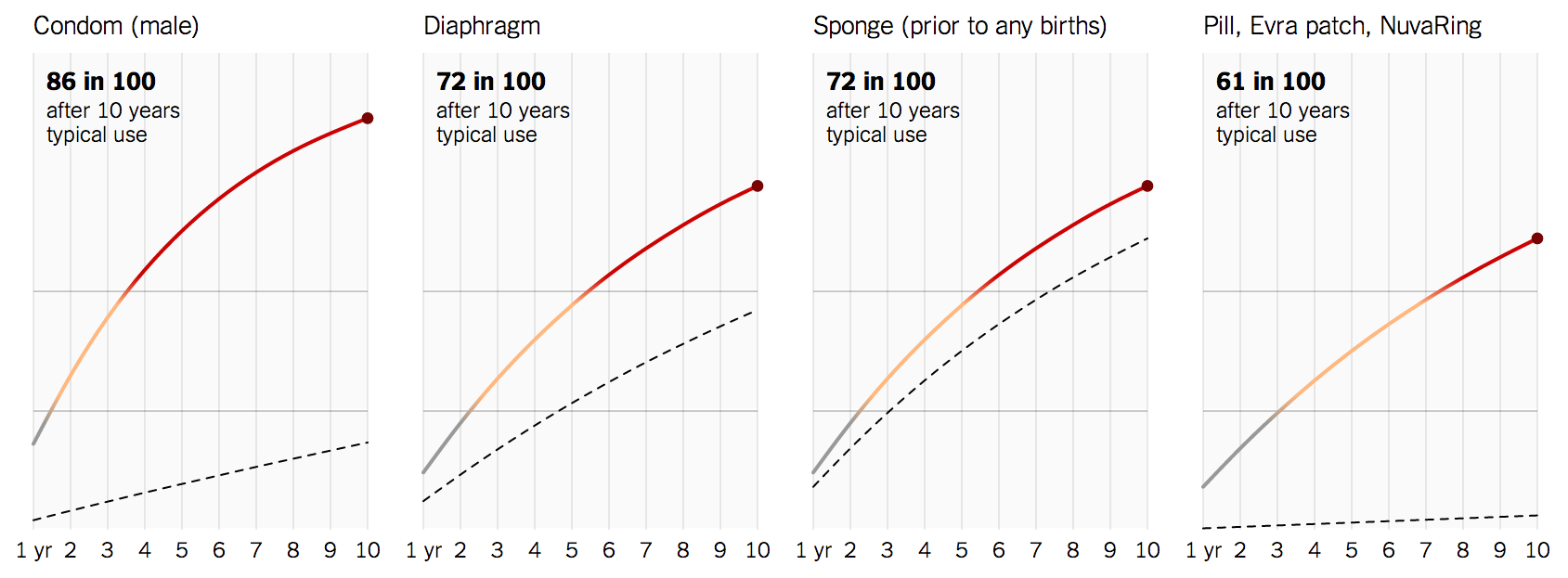
This should surely trigger a commonsense check: my peer group has been sexually active for at least ten years, and while many now have children, I don’t get any sense that so many were unplanned. My peers might be unusual, but still, these 10 year rates smell wrong.
Helpfully, the NYT is very upfront about their probabilistic methodology:
How the numbers were calculated: The probability that a woman doesn’t get pregnant at all over a given period of time is equal to the success rate of her contraceptive method, raised to the power of the number of years she uses that method.
And therein lies the problem. This formula works for so-called ‘identical and independent’ events, like die-rolling. If you roll two dice in turn, seeing a six on the first die doesn’t change the probability of seeing a six on the second die. That’s independence. Furthermore the probability of a six is the same on each die. That’s identical-ness (we really need a better word). Together, they means we can use some simple techniques to analyse more complicated outcomes.
Couples are like dice #
The probability of rolling a one on a single throw is 1/6, or about 16%. Conveniently, about the same as a couple’s probability of conceiving in one-year of typical male condom use, according to NYT.
\[\mathrm{P}(\textrm{rolling a one on any single throw}) = 0.16\]So think of rolling a one as ‘becoming pregnant in a particular year’. If we want to know the odds of rolling a one in any of ten throws, we work it out as follows:
P(rolling a one anywhere in ten throws)
= 1 - P(not rolling a one on throw 1 & not rolling a one on throw 2 & … & not rolling a one on throw 10)
= 1 - P(not rolling a one on throw 1) P(not rolling a one on throw 2) … P(not rolling a one on throw 10)
= 1 - {P(not rolling a one on any single throw)}^10
= 1 - 0.84^10
= 0.84 (coincidentally)
Further, this scales up to multiple dice in a simple multiplicative way, because dice are identical to one another. If we throw 100 dice, around 16 of them come up one on the first throw, and fully 84 of them will roll a one at least once.
To get from lines 2-3 and 3-4 above, we’ve made two crucial assumptions. Firstly, that throws are independent events (that’s what allows you to write P(A and B) = P(A) P(B); and secondly, that these events have identical probabilities (which allows us to write P(A1) P(A2) … P(An) = [P(A1)]^n). These are quite reasonable assumptions for die throwing. To scale up to 100 dice, we’ve again assumed identical-ness, this time between dice instead of between throws.
But human populations, unlike dice, are heterogenous, and this heterogeneity complicates things. It makes group averages, including risk statistics like contraceptive effectiveness, quite tricky.
Actually, couples are more like snowflakes #
Contraceptive stats are usually reported in two ways, which the CDC describes as follows:
Effectiveness can be measured during “perfect use,” when the method is used correctly and consistently as directed, or during “typical use,” which is how effective the method is during actual use (including inconsistent and incorrect use).
Crucially, typical use includes incorrect and inconsistent use. Putting a condom on backwards, thinking you’ve put on a condom when you really didn’t, not even attempting to use a condom because you’ve run out and Amazon doesn’t do drone delivery yet… these are all included in typical use. In other words, typical use is an average, and includes the ignorant, the foolish, the irresponsible.
But foolishness is not a random event: everyday experience shows it’s spread unevenly throughout the population. This means, for one thing, you have to be very careful applying typical use statistics to any particular individual - such as yourself. You might be a greater fool, in which case “your” typical effectiveness might be even worse than average, but you might be a lesser fool, an extremely-careful-verging-on-OCD person who always checks the direction of unrolling, squeezes out the air, counts the number of rows to the nearest emergency exit, and unplugs appliances when you go on holiday. Only you really know (but be honest, and remember the Dunning-Kruger effect: half of us really are worse than average).
This heterogeneity is a problem if you’re trying to aggregate over time, as the NYT article does. Our 100 couples are not like 100 identical dice, each of which has a 16% chance of rolling a one on a given roll. Instead imagine a different arrangement:
-
70 couples (call them “perfect use” couples) are like 50 sided dice, with only a 2% chance of rolling a one.
-
30 couples (call them “abstinence-only-sex-ed” couples) are like two-sided dice (bear with me), with a 50% chance of rolling a one.
Observe that on a given throw of 100 dice/couples, we would still expect 16 to come up one (50% of 30 plus 2% of 70 = 16).
But now consider what happens over ten throws. It helps to consider the two groups, which are internally homogenous, separately - then we can use the same calculation as above. For the “perfect use” couples,
\[\mathrm{P}(\textrm{rolling a one anywhere in 10 throws}) = 1 - (1 - 0.02)^{10} = 0.18\]so 18% of these 70 couples, or around 13, will become pregnant. For the “abstinence-only-sex-ed” couples
\[\mathrm{P}(\textrm{rolling a one anywhere in 10 throws}) = 1 - (1 - 0.5)^{10} = 0.999\]so every single one of these 30 couples will become pregnant. In fact, nearly all of them will have multiple pregnancies if they don’t change their behaviour, but that isn’t what matters for effectiveness. For that, what matters is the total number of couples, out of 100, that had at least one pregnancy in the period: 18+30 = 48 couples. (If you were wondering how heterogeneity connects to the independence and identical assumption, this is it: the effectiveness measure effectively applies to a population without replacement—once a couple has become pregnant once, whatever happens to them no longer matters—so the relevant underlying population is changing, in a dependent way, year on year.) [On reflection this is drawing a false connection between aggregation and independence: the problem here is one of aggregation. See my note above.]
48 is quite a bit lower than the original 84—and this reasoning applies to all the “typical use” curves the NYT reports. It probably applies, to a lesser extent, to some of the “perfect use” curves too, because even if you take user error out of the equation, birth control is going to be more or less effective for different couples because of biological heterogeneity. Exactly how much less the real figures will be depends on the underlying distribution of effectiveness (or foolishness, if you prefer), and I’ve never seen stats on that. I’d be willing to bet 48 is closer to the truth than 84, though.
And that’s why you shouldn’t believe everything you read in the New York Times. And also why should always keep a pencil, eraser, some quad-ruled notepaper, a calculator and a set of polyhedral dice next to the Durex/Trojans in your bedside drawer.

Add comment
Comments are moderated and will not appear immediately.
Comments (2)