Data visualization and truth
In the last week I have found myself arguing both that murder statistics should be expressed as population rates and that doing so can be quite misleading. That kind of apparently inconsistency deserves a quick explanation.
In the first example, I took issue with a Guardian article on an increase in murder rates in 2015, and in particular this chart:
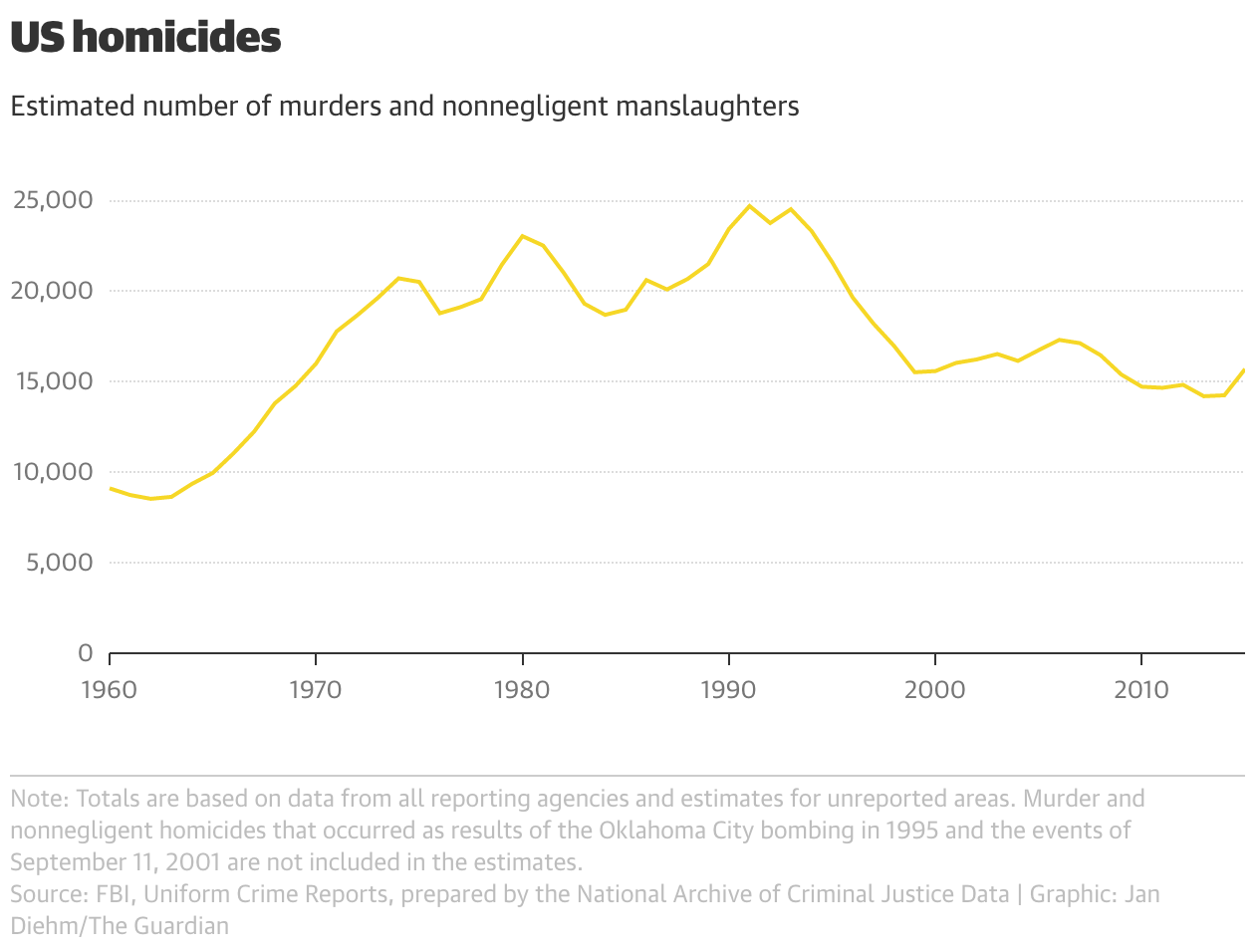
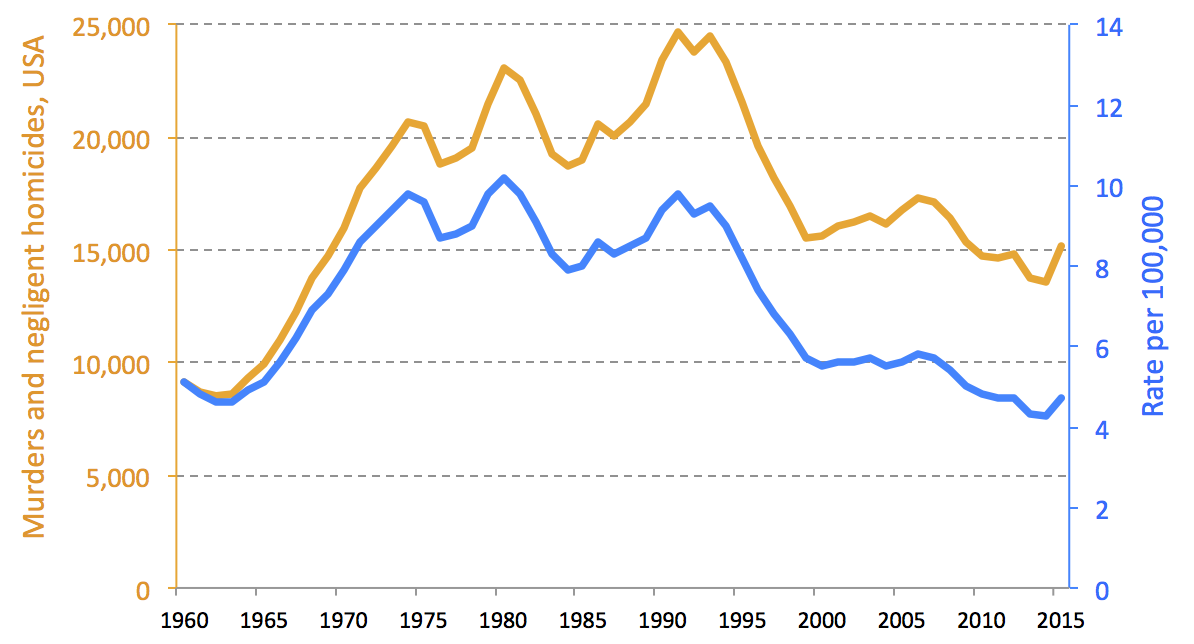
This seems like a clear-cut case of where raw data should be standardised by population. The US population has grown by nearly 80% between 1960 and 2015, which means the left and right sides of that chart are not really comparable. Since crime (like illness, unemployment, childbirth, etc.) is something that happens to a person, it makes sense to divide by the relevant population denominator.
That changes the picture quite a bit, as you can see in the below version. For one thing, in rates, it’s clear that murders in 2015 are still near to record lows (since 1960, anyway), whereas the unadjusted data would suggest a plateau at higher than 1960s levels.
The second example, murders in USA and Canada, was superficially very similar. Randal Olsen tweeted this chart from Reddit.
US and #Canada murder rate by State/Province. #datavizhttps://t.co/r3GNXeVm5Z pic.twitter.com/iGoHCWQTqm
— Randy Olson (@randal_olson) September 23, 2016
It depicts the murder rate per 100,000, exactly as I preferred for the Guardian chart. So why don’t I like it here? My complaint is that some of Canada’s northern provinces don’t even have 100,000 people. Consider Yukon (next to Alaska). It looks like a dangerous place, “8.1-10.0 murders per 100,000”—in the same category as Louisiana or Mississippi.
But if you actually look at the underlying raw data, you can see that Yukon had exactly 3 murders in 2014 (the most recent year available). Moreover, in each of the three previous years it had no murders at all.
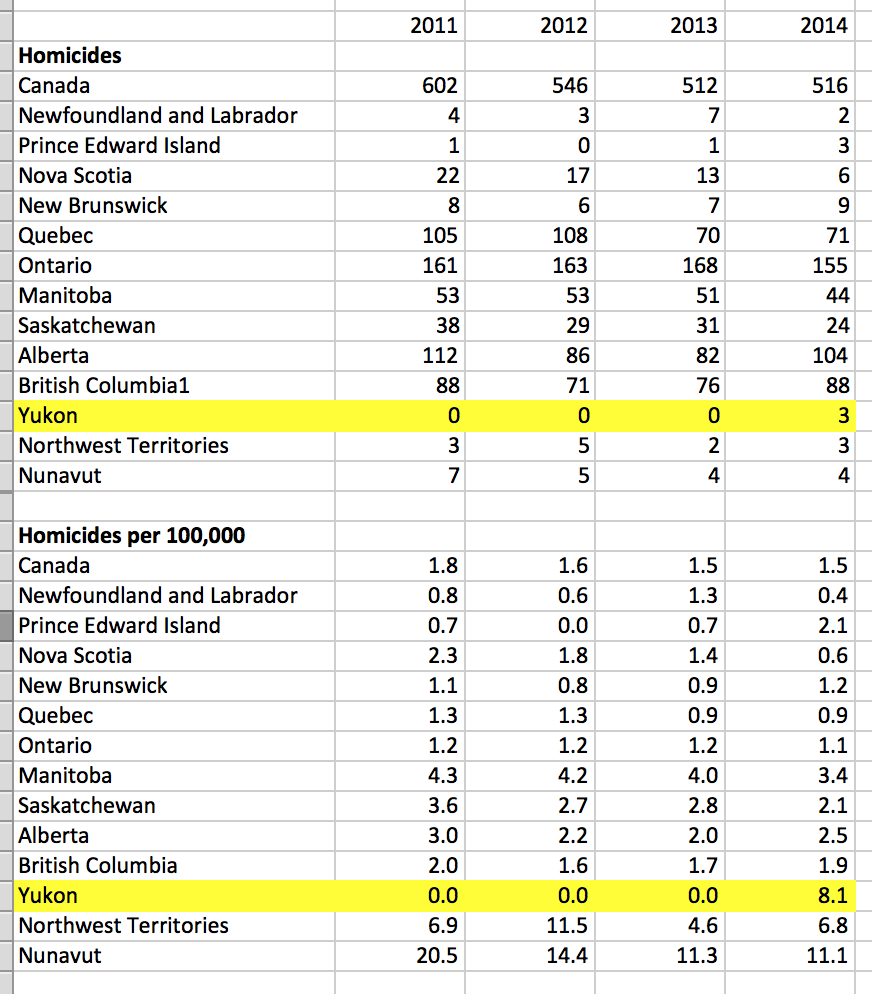
Over a four year period, Yukon’s actually a fairly safe place. But it has such a low population that a few incidents saw it jump from the bottom to the top of the rankings. (Notice, too, that unlike Yukon, the Nunavut rate is not only very high, but consistently so - so while Yukon probably doesn’t have a systemic problem, Nunavut probably does. But that’s not something you can see from the map above.)
I still think that population rates are the right thing to lead with here. I would just caution against showing only rates when the numerator quantity is very low counts, which are often inherently variable. Sometimes an asterisk and a footnote is all it takes to make this clear. Or, in this case, since the comparison is across geography, perhaps a four-year average could have been used, to smooth annual variation.
These two examples illustrate why data visualisation is as much an art as a science. In the first case, I think the raw data is misleading. In the second case, the rate is misleading. What is common in both is a kind of dishonesty-by-negligence. Although both are an objectively accurate depiction of the data, they each invite the viewer to draw conclusions that are not necessarily true (“US crime is at 1971 levels”, “northern Canadian provinces are hotbeds of homicide”).
When I create a visualization, I think I have a responsibility to anticipate the wrong conclusions people will draw, and use the visualisation to nudge viewers away from such unfounded. A dataset may not have any inherent ”truth”, but in a particular context or narrative it does, and the choice of visualization should reveal that rather than obscuring it.
Add comment
Comments are moderated and will not appear immediately.