Introduction to Wikidata using SPARQL
You’re certainly familiar with Wikipedia, but you may not be aware of Wikidata, which is an ongoing effort to structure some of the data underlying Wikipedia. Traditionally, facts (e.g. the population of New York City) are embedded in the text of a wiki, and there’s no easy way to automatically extract them. Wikipedia has a little more structure than this, but it’s still really designed for humans rather than machines.
Wikidata is the opposite - designed for machines, not humans.
It’s part of the broader semantic web movement, which aims to make the web more and more machine readable. Most of the time you don’t notice this, but when you run a query like “spouse of George Washington” and see this, rather than just a collection of links, that’s Google taking advantage of semantic web data (probably - they might also be using machine learning to infer it from unstructured text).
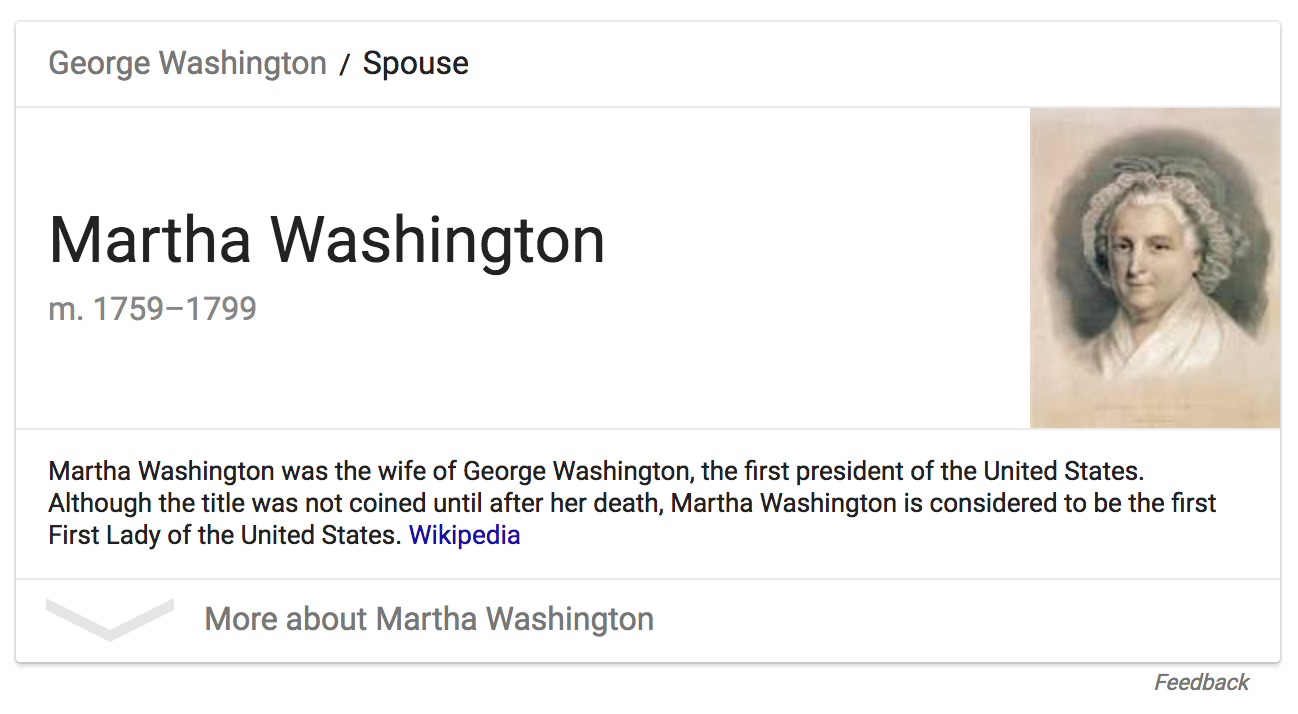
Google, internally, knows this fact:
The person Martha Washington was the spouse of the person George Washington.
This same fact is recorded in Wikidata like this:
where Q23 is Wikidata for “George Washington”, P26 for “spouse” and Q191789 for “Martha Washington”. Statements like this, in the form subject-predicate-object, are referred to as (semantic) triples.
Wikidata is basically just a giant database of triples like this. And we can this database using a query language called SPARQL, which is to triple databases as SQL is to relational databases. This turns out to be frequently useful for data science projects. For instance, I’ve used it in the past to query information about music and musicians, and more recently to find official and slang names for countries in different languages. How useful it is depends on how complete Wikidata is in your area of interest, but I find it’s often surprisingly complete.
So if we wanted to ask Wikidata the same question we just asked Google, we can write a query like this (you can run this at query.wikidata.org)
SELECT ?person
WHERE
{
?person wdt:P26 wd:Q23.
}
and when you run it, you should see wd:Q191789 as the answer.
An example like this is relatively straightforward, but SPARQL queries can quickly become complex. The key thing, I think, is to remember that it’s really just pattern matching. So if we wanted to query _all spouses of all US Presidents, _we just add more patterns that must match (plus some magic to get the “labels” - ie. names - of these entities).
SELECT ?spouse ?spouseLabel WHERE {
?person wdt:P39 wd:Q11696 .
?person wdt:P26 ?spouse .
SERVICE wikibase:label {
bd:serviceParam wikibase:language "en" .
}
}
The key part here is in bold. It says find
-
a person (call them ?person) who “held the position” (wdt:P39) President of the United States of America (wd:Q11696); and, where
-
that person (?person) “has a spouse” (wdt:P26) (call them ?spouse)
The rest just gets the label (ie. name) of the spouse in English.
Of course you have to be careful with crowd-sourced data like this. This query returns for me:
-
Martha Washington
-
Michelle Obama
-
…
-
Abbey Bartlett
-
Claire Underwood
But wait - those last two are fictional spouses of fictional US Presidents (in The West Wing and the Netflix remake of House of Cards). It turns out that in Wikidata, P39 “holding the position of President of the United States of America” can apply to fictional people too.
It’s hard to say if this is an error with our query, or an error in Wikidata - after all, these people were indeed spouses of US Presidents, in a certain context. Wikidata knows this (probably) because on the Wikipedia page for the fictional character Josiah Bartlett, it lists “Occupation: President of the United States”. The lesson is, when we’re dealing with computers, we have to be quite specific about what we mean.
There are two ways we might rectify this. One is to specify that we’re only interested in real (not fictional) Presidents (but then what about fictional spouses of real Presidents?). That looks like this:
SELECT ?spouse ?spouseLabel WHERE {
?person wdt:P39 wd:Q11696 .
?person wdt:P26 ?spouse .
<strong> ?person wdt:P31 wd:Q5 .</strong>
SERVICE wikibase:label {
bd:serviceParam wikibase:language "en" .
}
}
Where the added (bold) line says exactly: “the person must be an instance of a person” (which appears to only be used for real people. We can find spouses of fictional Presidents but substituting Q15632617 (fictional human) for Q5 (human).
Because Wikipedia is so complex (or, perhaps, because reality is so complex), there is usually more than one way to phrase a query. This tutorial suggests another way to answer the same question, using a head of government of the United States relationship.
SELECT ?spouse ?spouseLabel WHERE {
wd:Q30 p:P6/ps:P6 ?person .
?person wdt:P26 ?spouse .
SERVICE wikibase:label {
bd:serviceParam wikibase:language "en" .
}
}
Interestingly, this results in one more result than the other query. I haven’t dug into which spouse it is (or more than one) or why. Another lesson to take away from this is that this kind of query isn’t going to be perfect: between ambiguities in expression (is Ivana Trump the spouse of a US President, or do you have to be married while the office is held to count?) and incompleteness/errors in crowdsourced data, it’s only an approximate answer.
But often in data science applications, this is good enough. I think semantic data is amazing, and I wish I saw it used more often.
There’s a great set of example queries to learn from here.
Add comment
Comments are moderated and will not appear immediately.