What is big data?
People often ask me: What is big data? The answer I usually give is
Any data too large to process using your normal tools & techniques.
That’s a very context dependent answer: last week in one case it meant one million records, too big for Stata on a laptop, and in another it meant a dataset growing at about 1TB per day. To put it another way, big data is anything where you have to think about the engineering side of data science: where you can’t just open up R and run lm(), because that would take a day and need a terabyte of memory.
These days, people know all about map/reduce. It’s some big data processing paradigm Google invented in the mid-2000s, right? You can read what IBM has to say on that.
But don’t be too sure, because here is a map() function from 1946.

It’s an IBM 519 Document-Originating Machine. It’s pretty straightforward really. You load in the cards, wire up the control panel for whatever function you want, and start it running - at a breathtaking 100 cards per minute.
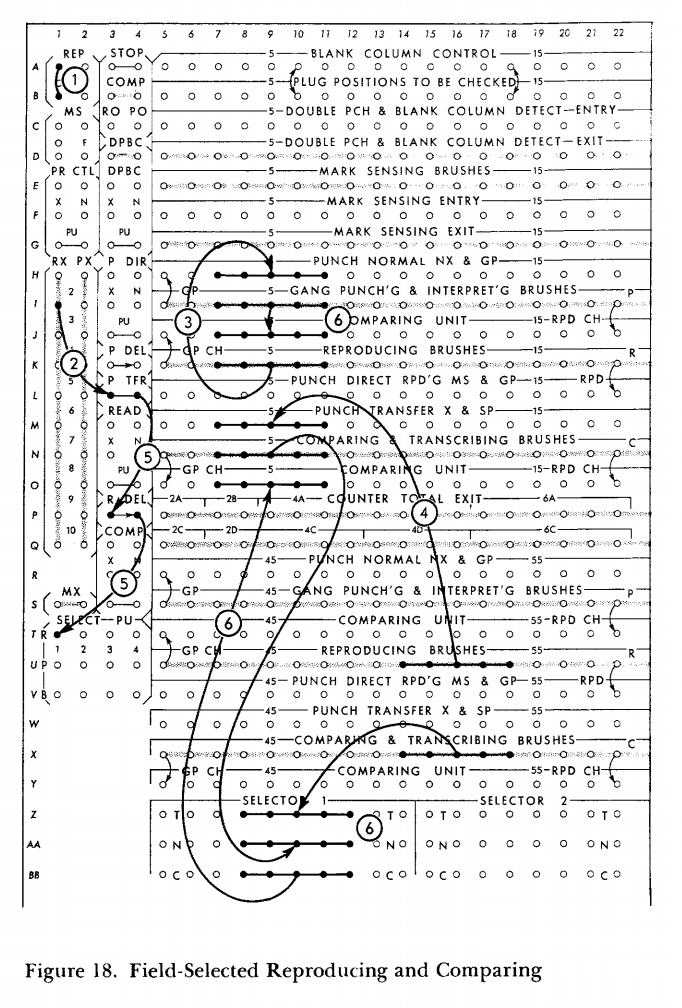
And right, the panel configuration for “field-selected reproducing and comparing”, basically a SQL SELECT statement, with a check afterwards (because reproducing punch cards is an error-prone business).
Also, here is a reduce() function from 1949, an IBM 407 Accounting Machine. It reads in a stack of cards and prints out summary statistics on them, totals, subtotals, etc.

Technologies change, but the basic approaches to processing data remain the same. The low-level, procedural, mechanical mode of thinking needed for this sort of equipment seemed to go away when randomly-seekable hard drives got cheap enough and relational databases came along in the 1970s. They offered a pure, set-theoretic way to think about your data. This is mostly what I learnt in undergraduate computer science.
Then, for a time, web-scale data outgrew databases, and Hadoop forced everyone to think in terms of low-level constructs again. Even though you might be writing a Spark job in a high-level interpreted language and running it on terabytes of data, you’re basically just hooking up pieces of unit-record equipment.
Today, that end-of-month payroll job that might have taken hours to process through a room of IBM equipment takes milliseconds on a desktop accounting package. The same, eventually, will be true for most of what constitutes “big data” today - once the tools catch up. But then some, newer, bigger data will come along, and it will again reward people to work a little “closer to the metal”. The cycle never ends…
Add comment
Comments are moderated and will not appear immediately.